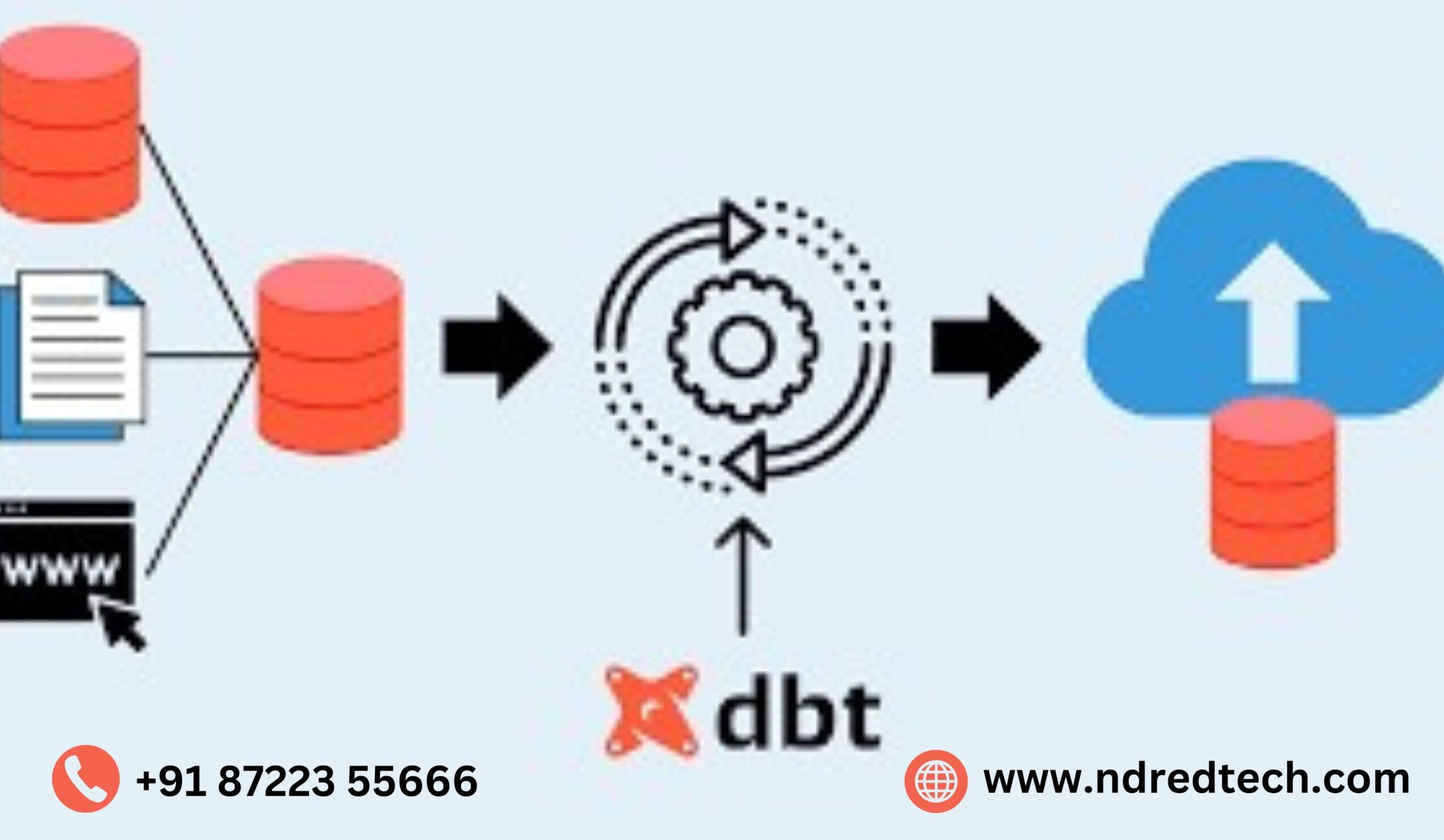
1.What is DBT?
DBT, short for Data Build Tool, is an open-source data transformation and modeling tool. It helps analysts and data engineers manage the transformation and preparation of data for analytics and reporting.
2.What are the primary use cases of DBT?
Dbt is primarily used for data transformation, modeling, and preparing data for analysis and reporting. It is commonly used in data warehouses to create and maintain data pipelines.
3.How does DBT differ from traditional ETL tools?
Unlike traditional ETL tools, DBT focuses on transforming and modeling data within the data warehouse itself, making it more suitable for ELT (Extract, Load, Transform) workflows. DBT leverages the power and scalability of modern data warehouses and allows for version control and testing of data models
4.What is a DBT project?
A DBT project is a directory containing all the files and configurations necessary to define data models, tests, and documentation. It is the primary unit of organization for DBT.
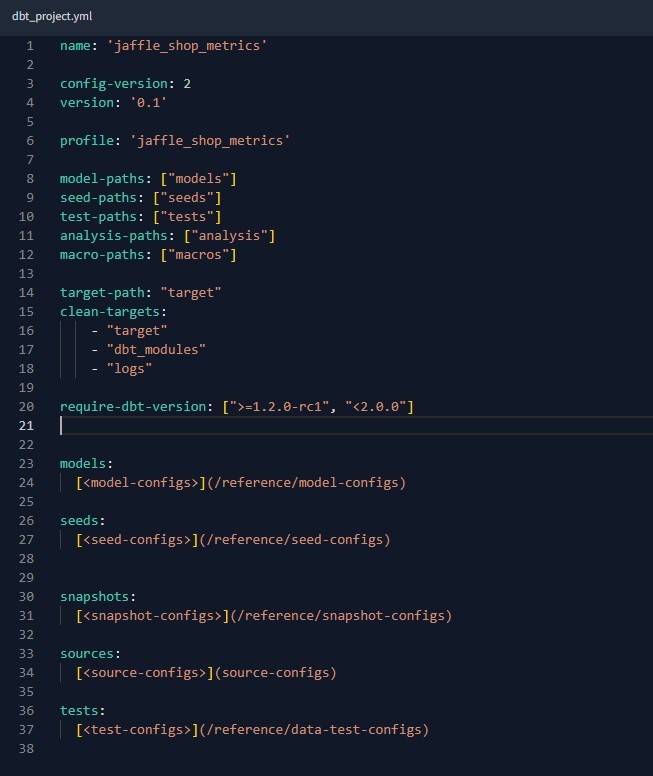
5. Explain the difference between source and model in DBT?
A source in DBT refers to the raw or untransformed data that is ingested into the data warehouse. Models are the transformed and structured datasets created using DBT to support analytics.
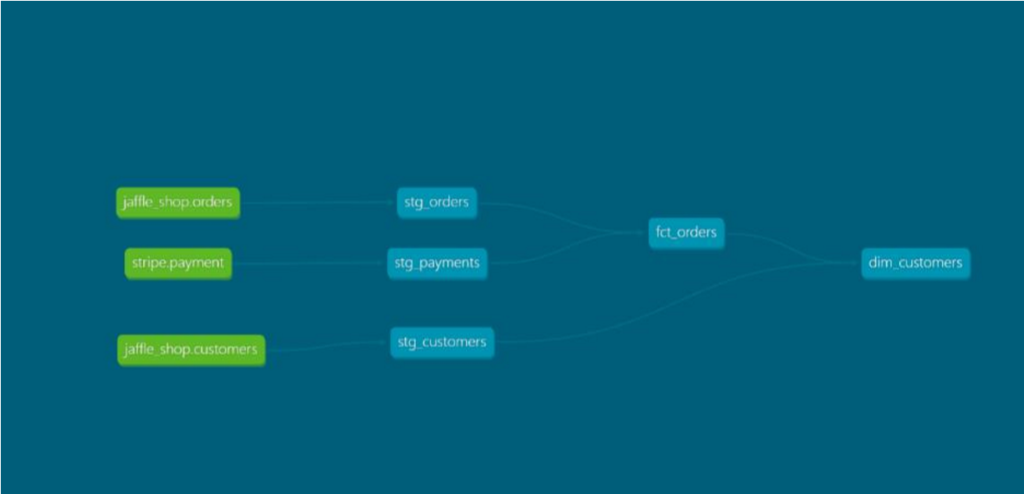
6. What is a DAG in the context of DBT?
DAG stands for Directed Acyclic Graph, and in the context of DBT, it represents the dependencies between models DBT uses a DAG to determine the order in which models are built.
Example –
7.How can you perform testing and validation of DBT models?
You can perform testing in DBT by writing custom SQL tests to validate your data models. These tests can check for data quality, consistency, and other criteria to ensure your models are correct.
8.Explain the process of deploying DBT models to production.
Deploying DBT models to production typically involves using DBT Cloud, CI/CD pipelines, or other orchestration tools. You’ll need to compile and build the models and then deploy them to your data warehouse environment.
9.How does DBT support version control and collaboration?
DBT integrates with version control systems like Git, allowing teams to collaborate on DBT projects and track changes to models over time. It provides a clear history of changes and enables collaboration in a multi-user environment.
10.What are some common performance optimization techniques for DBT models?
Performance optimization in DBT can be achieved by using techniques like materialized views, optimizing SQL queries, and using caching to reduce query execution times.
11.How do you monitor and troubleshoot issues in DBT?
DBT provides logs and diagnostics to help monitor and troubleshoot issues. You can also use data warehouse-specific monitoring tools to identify and address performance problems.
12.Can DBT work with different data sources and data warehouses?
Yes, DBT supports integration with a variety of data sources and data warehouses, including Snowflake, Big Query, Redshift, and more. It’s adaptable to different cloud and on-premises environments.
13.How does DBT handle incremental loading of data from source systems?
DBT can handle incremental loading by using source freshness checks and managing data updates from source systems. It can be configured to only transform new or changed data.
14.What security measures does DBT support for data access and transformation?
DBT supports the security features provided by your data warehouse, such as row-level security and access control policies. It’s important to implement proper access controls at the database level.
15.How can you manage sensitive data in DBT models?
Sensitive data in DBT models should be handled according to your organization’s data security policies. This can involve encryption, tokenization, or other data protection measures.
16.What is seed?
A “seed” refers to a type of dbt model that represents a table or view containing static or reference data. Seeds are typically used to store data that doesn’t change often and doesn’t require transformation during the ETL (Extract, Transform, Load) process.
Here are some key points about seeds in dbt:
- Static Data: Seeds are used for static or reference data that doesn’t change frequently. Examples include lookup tables, reference data, or any data that serves as a fixed input for analysis.
- Initial Data Load: Seeds are often used to load initial data into a data warehouse or data mart. This data is typically loaded once and then used as a stable reference for reporting and analysis.
- Static Data: Seeds are used for static or reference data that doesn’t change frequently. Examples include lookup tables, reference data, or any data that serves as a fixed input for analysis.
Here’s an example of a dbt seed YAML file:
version: 2 sources:
- name: my_seed_data tables:
- name: my_seed_table seed:
freshness: { warn_after: ‘7 days’, error_after: ’14 days’ }
17.What is Pre-hook and Post-hook?
Pre-hooks and Post-hooks are mechanisms to execute SQL commands or scripts before and after the execution of dbt models, respectively. dbt is an open-source tool that enables analytics engineers to transform data in their warehouse more effectively.
Here’s a brief explanation of pre-hooks and post-hooks:
1.Pre-hooks:
- A pre-hook is a SQL command or script that is executed before running dbt models.
- It allows you to perform setup tasks or run additional SQL commands before the main dbt modeling process.
- Common use cases for pre-hooks include tasks such as creating temporary tables, loading data into staging tables, or performing any other necessary setup before model execution
Example of a pre-hook :– models/my_model.sql
{{ config(
pre_hook = "CREATE TEMP TABLE my_temp_table AS SELECT * FROM my_source_table"
) }} SELECT column1, column2 FROM
my_temp_table
2.Post-hooks:
- A post-hook is a SQL command or script that is executed after the successful completion of dbt models.
- It allows you to perform cleanup tasks, log information, or execute additional SQL commands after the models have been successfully executed.
- Common use cases for post-hooks include tasks such as updating metadata tables, logging information about the run, or deleting temporary tables created during the pre-hook.
Example of a post-hook : — models/my_model.sql
SELECT column1, column2 FROM my_source_table {{ config(
post_hook = "UPDATE metadata_table SET last_run_timestamp = CURRENT_TIMESTAMP"
) }} 18.what is snapshots?
“snapshots” refer to a type of dbt model that is used to track changes over time in a table or view. Snapshots are particularly useful for building historical reporting or analytics, where you want to analyze how data has changed over different points in time.
Here’s how snapshots work in dbt:
- Snapshot Tables: A snapshot table is a table that represents a historical state of another table. For example, if you have a table representing customer information, a snapshot table could be used to capture changes to that information over time.
- Unique Identifiers: To track changes over time, dbt relies on unique identifiers (primary keys) in the underlying data. These identifiers are used to determine which rows have changed, and dbt creates new records in the snapshot table accordingly.
- Timestamps: Snapshots also use timestamp columns to determine when each historical version of a record was valid. This allows you to query the data as it existed at a specific point in time.
- Configuring Snapshots: In dbt, you configure snapshots in your project by creating a separate SQL file for each snapshot table. This file defines the base table or view you’re snapshotting, the primary key, and any other necessary configurations.
Here’s a simplified example:– snapshots/customer_snapshot.sql
{{ config(
materialized='snapshot', unique_key='customer_id', target_database='analytics', target_schema='snapshots', strategy='timestamp'
) }}
SELECT customer_id, name, email, address,
current_timestamp() as snapshot_timestamp FROM
source.customer; 19.What is macros?
macros refer to reusable blocks of SQL code that can be defined and invoked within dbt models. dbt macros are similar to functions or procedures in other programming languages, allowing you to encapsulate and reuse SQL logic across multiple queries.
Here’s how dbt macros work:
- Definition: A macro is defined in a separate file with a sql extension. It contains SQL code that can take parameters, making it flexible and reusable
Example – my_macro.sql
{% macro my_macro(parameter1, parameter2) %} SELECT column1, column2 FROM my_table WHERE
condition1 = {{ parameter1 }}
AND condition2 = {{ parameter2 }}
{% endmacro %} 2.Invocation: You can then use the macro in your dbt models by referencing it.
My_model.sql
{{ my_macro(parameter1=1, parameter2='value') }} When you run the dbt project, dbt replaces the macro invocation with the actual SQL code defined in the macro.
3.Parameters: Macros can accept parameters, making them dynamic and reusable for different scenarios. In the example above, parameter1 and parameter2 are parameters that can be supplied when invoking the macro.
4.Code Organization: Macros help in organizing and modularizing your SQL code. They are particularly useful when you have common patterns or calculations that need to be repeated across multiple models.
My_model.sql
{{ my_macro(parameter1=1, parameter2='value') }}
-- another_model.sql
{{ my_macro(parameter1=2, parameter2='another_value') }} 20.what is project structure?
A project structure refers to the organization and layout of files and directories within a dbt project. dbt is a commandline tool that enables data analysts and engineers to transform data in their warehouse more effectively. The project structure in dbt is designed to be modular and organized, allowing users to manage and version control their analytics code easily.
A typical dbt project structure includes the following key components:
- Models Directory:
This is where you store your SQL files containing dbt models. Each model represents a logical transformation or aggregation of your raw data. Models are defined using SQL syntax and are typically organized into subdirectories based on the data source or business logic.
2.Data Directory:
The data directory is used to store any data files that are required for your dbt transformations. This might include lookup tables, reference data, or any other supplemental data needed for your analytics.
3.Analysis Directory:
This directory contains SQL files that are used for ad-hoc querying or exploratory analysis. These files are separate from the main models and are not intended to be part of the core data transformation process.
4.Tests Directory:
dbt allows you to write tests to ensure the quality of your data transformations. The tests directory is where you store YAML files defining the tests for your models. Tests can include checks on the data types, uniqueness, and other criteria.
5.Snapshots Directory:
Snapshots are used for slowly changing dimensions or historical tracking of data changes.
The snapshots directory is where you store SQL files defining the logic for these snapshots.
6.Macros Directory:
Macros in dbt are reusable pieces of SQL code. The macros directory is where you store these macros, and they can be included in your models for better modularity and maintainability.
7.Docs Directory:
This directory is used for storing documentation for your dbt project. Documentation is crucial for understanding the purpose and logic behind each model and transformation.
8.dbt_project.yml:
This YAML file is the configuration file for your dbt project. It includes settings such as the target warehouse, database connection details, and other project-specific configurations.
9.Profiles.yml:
This file contains the connection details for your data warehouse. It specifies how to connect to your database, including the type of database, host, username, and password.
10.Analysis and Custom Folders:
You may have additional directories for custom scripts, notebooks, or other artifacts related to your analytics workflow.
Having a well-organized project structure makes it easier to collaborate with team members, maintain code, and manage version control. It also ensures that your analytics code is modular, reusable, and easy to understand.
my_project/
|-- analysis/
| |-- my_analysis_file.sql
|-- data/
| |-- my_model_file.sql
|-- macros/
| |-- my_macro_file.sql |-- models/
| |-- my_model_file.sql
|-- snapshots/
| |-- my_snapshot_file.sql
|-- tests/
| |-- my_test_file.sql
|-- dbt_project.yml